[UPDATE 25/02/2013: iTunes 11 was released towards the end of 2012. It introduces (in the comments Paul points out the column browser function did exist in iTunes before version 11) the ‘column browser’ which allows you to navigate your music collection by multiple ‘facets’. The ‘Column Browser’ can only be used when a list is displayed in ‘List’ (as opposed to ‘Grid’ or ‘Artist’) view. To display the column browser, go to the ‘List’ view for a playlist, then (on a Mac at least) use the ‘View’ menu to ‘Show Column Browser’. Once the Column Browser is active you can decide which fields from the item records display in the column browser.
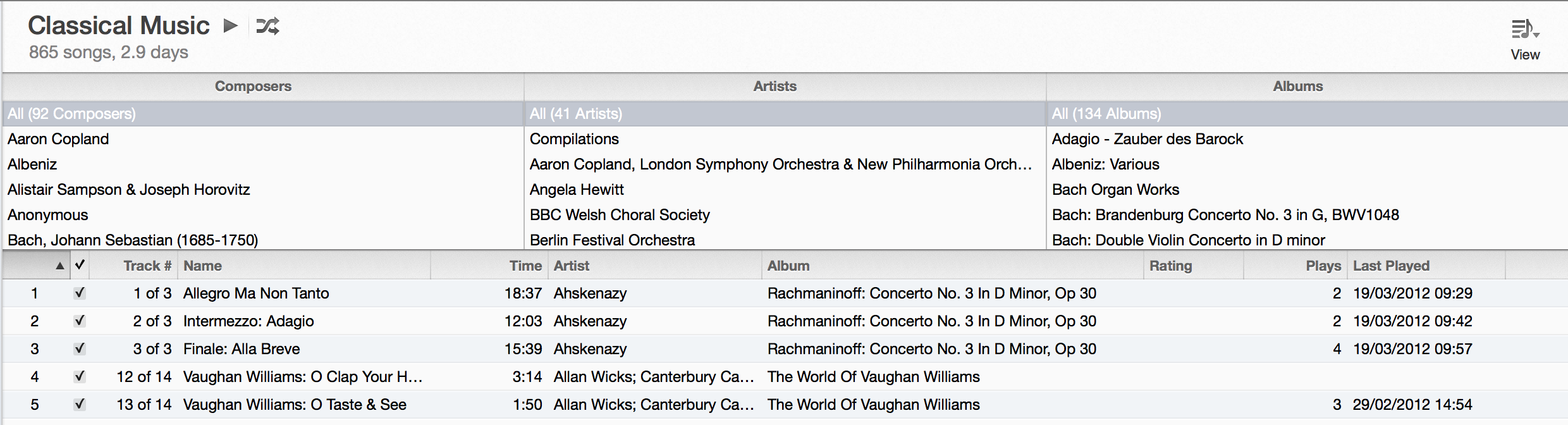
The Column Browser seems to be visible in the ‘Classical’ smart playlist by default, with the three columns chosen as ‘Composers’, ‘Artists’ and ‘Albums’. However, you can also display ‘Groupings’ (which were displayed by default for Classical music in iTunes 10 – see note below).
A final thing to note is that there are a couple of options with the Column Browser which are turned on by default and (in my opinion) work better turned off. These are ‘Group Compilations’ (which means when you have a variety of music on a single disc marked as a compilation, you don’t see these broken down by artist) and ‘Use Album Artists’.]
[UPDATE 29/07/2011: I’ve just noticed that in iTunes 10, if you use the ‘Classical’ smart playlist that comes pre-setup on the software, the display is different from all other iTunes screens, with the Composer appearing automatically on the left, followed by a ‘Grouping’ column, and finally the track listing. I need to have a play around to find what works best, but I think it pushes towards using ‘Groupings’ to define the ‘Piece’ – the iTunes release notes (at time of writing at http://www.apple.com/itunes/features/) say “You can also use iTunes Groupings to specify Works” (for library geeks, interesting use of FRBR terminology there)]
A quick post inspired by Chris Keene who recently asked:
On itunes, should classical music ‘Artist’ be the composer or conductor?
Since I had similar questions around entering classical music into iTunes I thought I’d just note down quickly the method I’ve settled on, and why.
iTunes isn’t really well designed (some would say I could stop right there) for handling music metadata beyond the basic stuff you might need for a collection of popular music. The data entry, and the browse interface, tends to focus on:
- Name (of track)
- Artist (single field)
- Album
While this seems to work relatively well for my collections of pop and jazz (although my jazz collection is small and I’m not so bothered about detailed metadata), it doesn’t do so well for my classical collection. I’m not sure this is a problem isolated to classical music, and I suspect it is about specific forms of music as well.
The type of thing I found didn’t work well was an album containing several pieces of music with multiple movements. So, for example, I had a CD of Anne-Sophie Mutter playing Mozart’s 3rd and 5th Violin Concertos, with the Berlin Philharmonic, conducted by Herbert von Karajan. The track listing on the CD looks something like this:
Konzert Für Violine Und Orchester Nr. 3 G-dur KV 216
1. Allegro
2. Adagio
3. Rondeau. AllegroKonzert Für Violine Und Orchester Nr. 5 A-dur KV 219
4. Allegro Aperto
5. Adagio
6. Rondeau. Tempo di Menuetto
Unlike a typical pop album, this track listing is not a useful in terms of the ‘Album’ (CD). This is where we can immediately see the fact that the physical item (the CD) was an artificial way of bundling two pieces of music together. So the first thing I do is to treat the CD as being comprised of two albums – one of violin concerto no. 3 and one of violin concerto no. 5. Once I’ve separated the music from the physical constraints of the CD, there seems little benefit to treating this as a single ‘album’. This is not always the completely the case – ‘The Kreisler Album’ on which Joshua Bell plays a variety of pieces by Fritz Kreisler is probably still worth treating as an album – I tend to make these decisions on a piece by piece basis.
Back to Mozart and Anne-Sophie Mutter:
Having now got an iTunes Album of Mozart Violin Concerto No. 3, with the tracks:
- Allegro
- Adagio
- Rondeau. Allegro
I could enter the details with “Violin Concerto No. 3” as the Album title, and the movements as the track titles. I use the ‘Track Number’ to make sure the movements are going to play in the right order if I play the ‘album’.
I can add Mozart as the ‘Composer’, and I have to make a decision about ‘artist’ – in this case I’m most interested in the fact the soloist is Anne-Sophie Mutter, so this is what I go for, but equally well I could have entered Karajan or even the Berlin Philharmonic – again these decisions can only be made on an individual basis – iTunes just isn’t up to anything more here 🙁 If I want to, I dump the rest of the ‘artist’ information in the ‘Comments’ field. My general rules would be to use the soloist if there is one, and the conductor for orchestral pieces, and if it is a chamber group I’d probably use their name – but these aren’t hard and fast rules – it’s a personal collection, not a library catalogue 🙂
However, even with all this information entered, I still found some irritations when using iTunes to browser my music collection. Although I could add the Composer to the browse interface, it is empty for almost all my non-classical music (and a pain to have an empty column taking up screen estate much of the time), and when sorting by Album, all the Symphonies/Concertos etc. bunch together (as the ‘Album’ is just called “Symphony No. 1”), so I end up having to flick between two columns to know what the piece actually is (i.e. to see the composer is Beethoven etc.)
So, I decided to add the composer information (abbreviated) into the Album title. So now rather than just “Violin Concerto No. 3”, I enter “Mozart: Violin Concerto No. 3”
This is what the entry for the 1st movement of the violin concerto looks like:

And this is how it looks in the iTunes browsing interface:

I have played around with adding numbers in at the start of the movement names (and in some cases the movements of a piece are explicitly numbered anyway), and overall it is far from perfect, but it works pretty well for me.