This is the fifth and last post in a series of 5.
In Part 4 I described how I used OpenRefine to fix issues with MARC records. In this fifth and final blog post in this series I’m going to cover exporting the mnemonic MARC records from OpenRefine and back to MarcEdit to produce a file of valid MARC records.
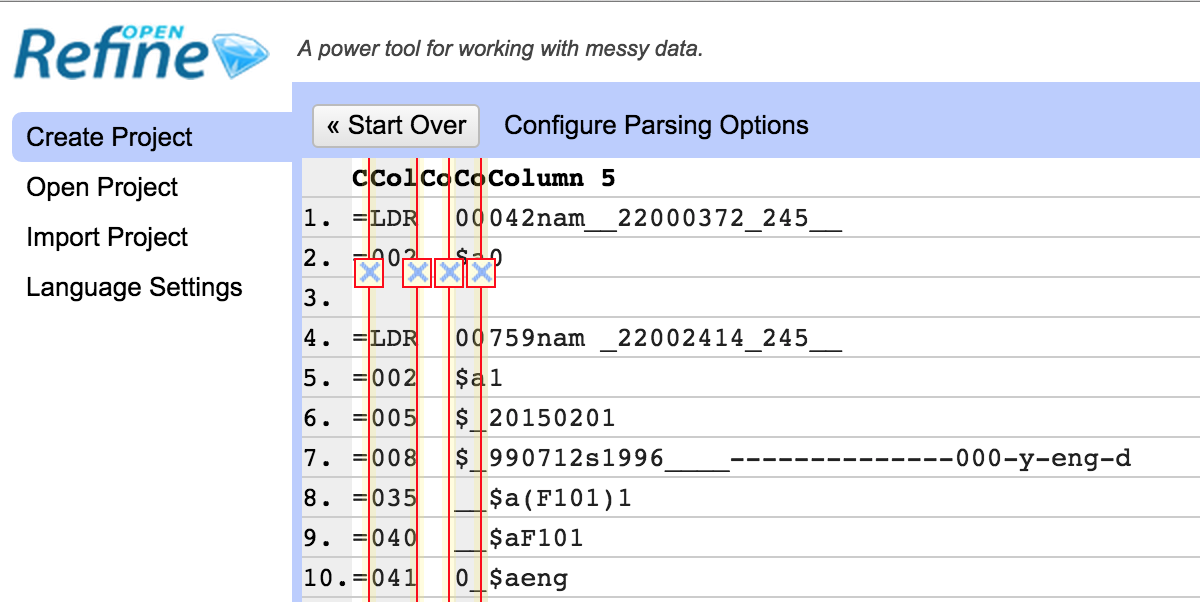
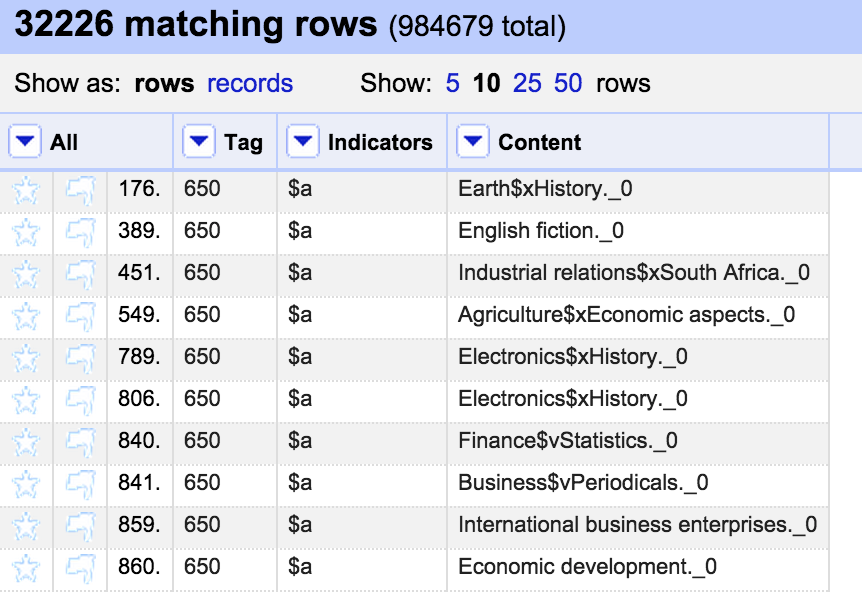
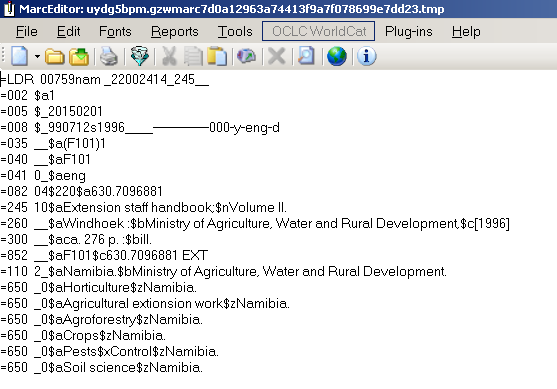
The mnemonic MARC format consists of one line per MARC field. Each line starts with an ‘=’ sign, followed immediately by the three digit/letter tag, which in turn is followed by two spaces. For fixed length fields the spaces are followed by the contents of the field. For other MARC fields the spaces are followed by the two indicators for the field, and then the content of the field (subfields marked with a ‘$’ signs):
=LDR 00759nam _22002414_245__ =001 000000001 ... =245 10$aExtension staff handbook;$nVolume II.
Where you have multiple records they are separated by a single blank line.
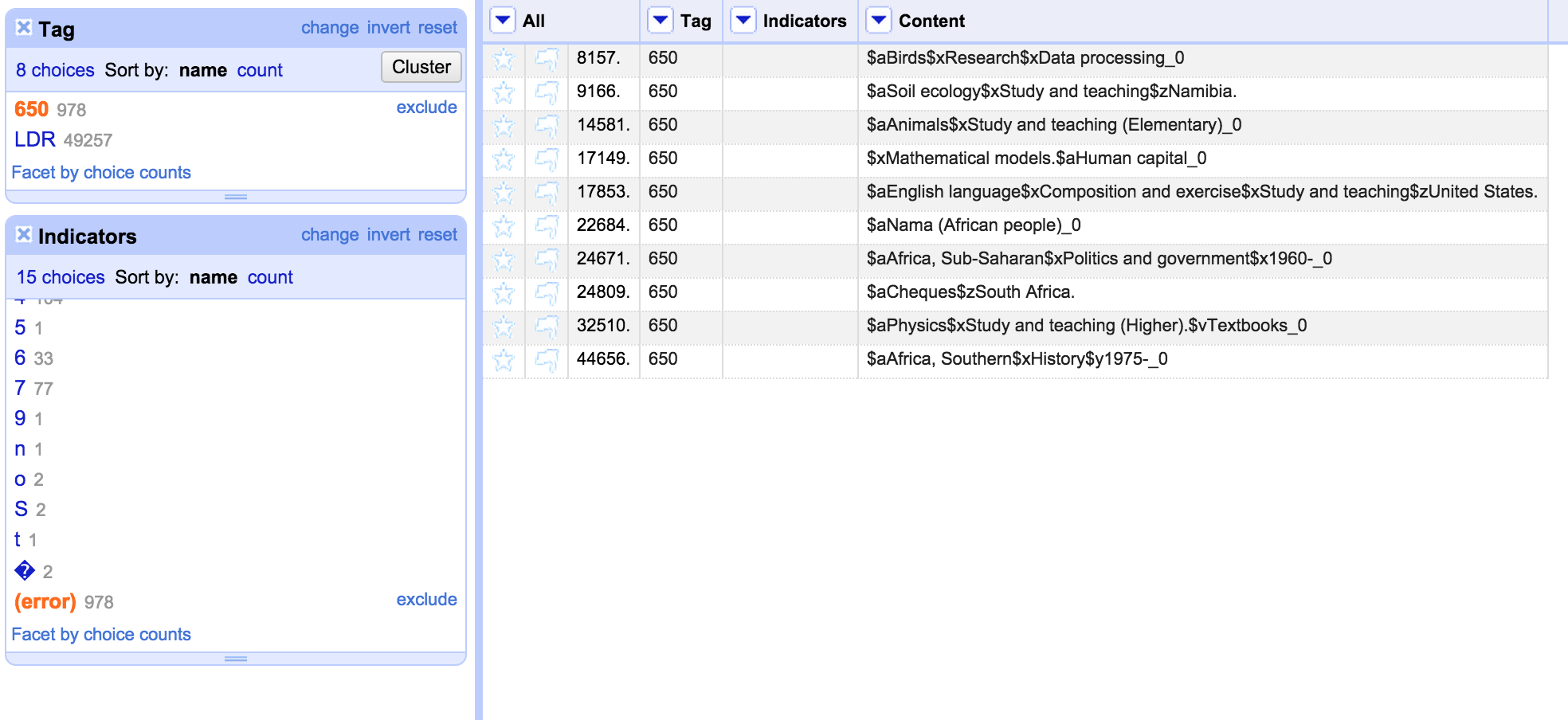
When I imported the file into OpenRefine I had put the information into three columns – one containing the MARC field tag, one containing indicators (blank for fixed fields) and one containing the field contents. However, I’d kept the blank lines that were in the original file and not done any sorting that would lose the order of the original file contents (I had removed some lines completely, but none of the blank lines). This is important because preserving the ordering and the blank lines from the original file is the only way the ‘records’ are preserved. I could have done some work in OpenRefine to link each field to a record ID, and then not worried about the blank lines and ordering, but to be honest that was extra work that wasn’t necessary in this case.
There are a number of export options in OpenRefine, all accessed from an ‘Export’ menu in the top right of the screen:
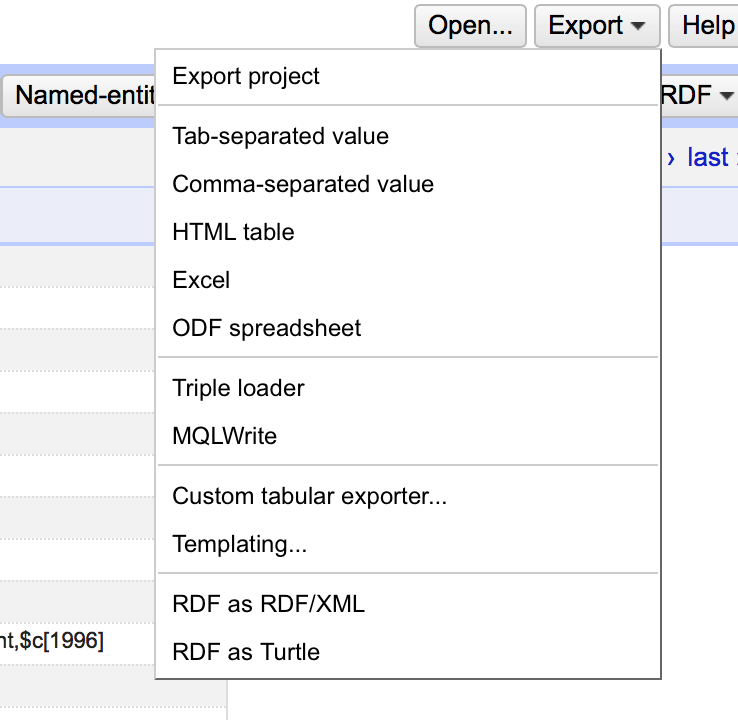
It is worth remembering that when exporting data from OpenRefine the default is to only export data that is in the current OpenRefine display – observing any filters etc you have applied to the data. So if you want to export the whole data set, make sure you remove any facets/filters before doing so.
As well as a number of standard formats, the “Custom tabular exporter” and “Templating” options allow you to build exports to your own specification. In this case I needed to use the “Templating” option which is the most flexible way of configuring exports.
The Templating option allows you to fully configure how each field in your OpenRefine project is exported. It also allows you to specify how records are separated and any header (prefix) or footer (suffix) you want in the complete export.
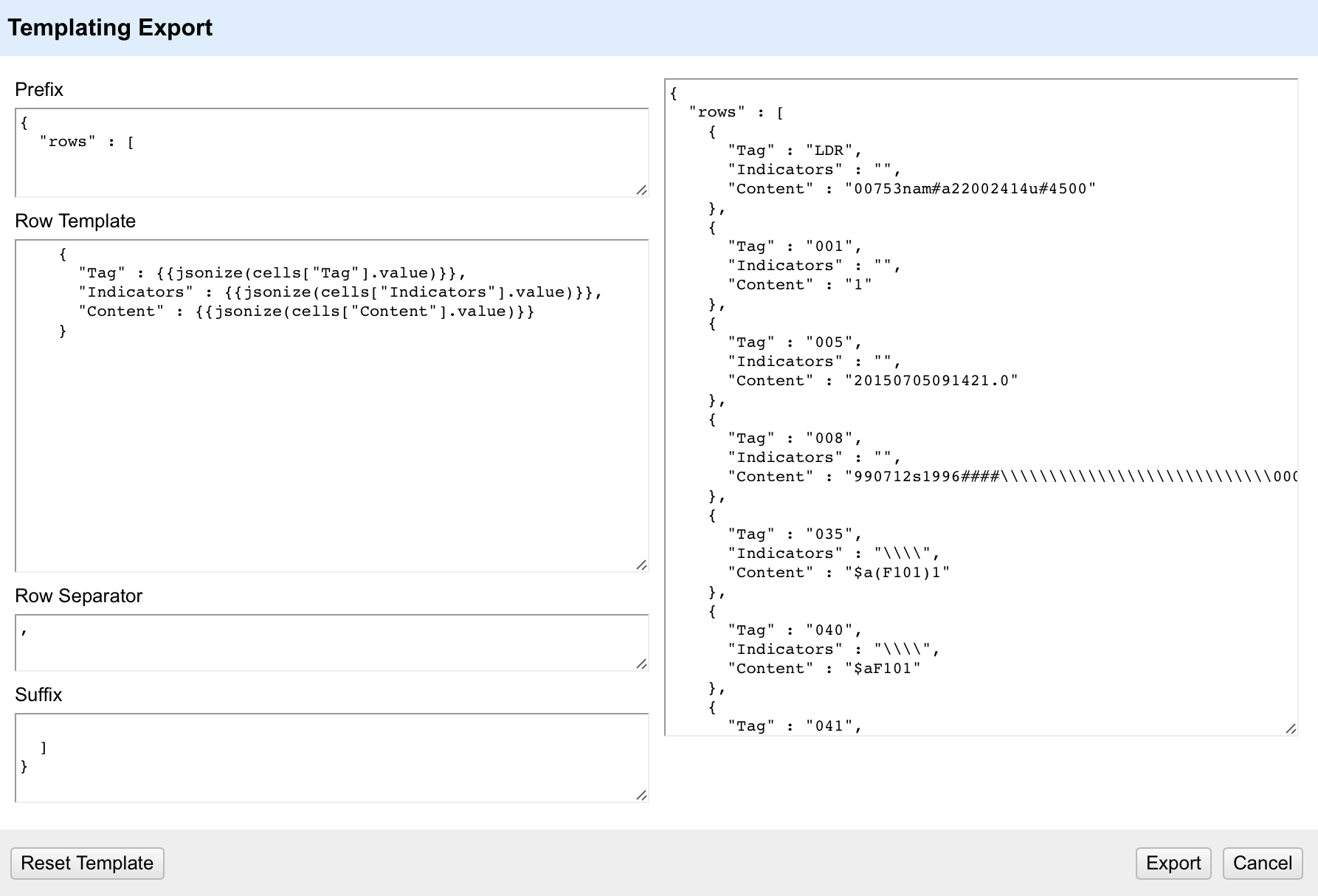
The default layout is a format called ‘JSON’ (Javascript Object Notation, but it doesn’t really matter). However we can completely re-write this into whatever format we want. The ‘Prefix’ and ‘Suffix’ areas on this form as simple text – you can just type whatever you want in here. Since in the case of mnemonic MARC file there are no headers or footers, I can remove all the text from the ‘Prefix’ and ‘Suffix’ areas in this form.
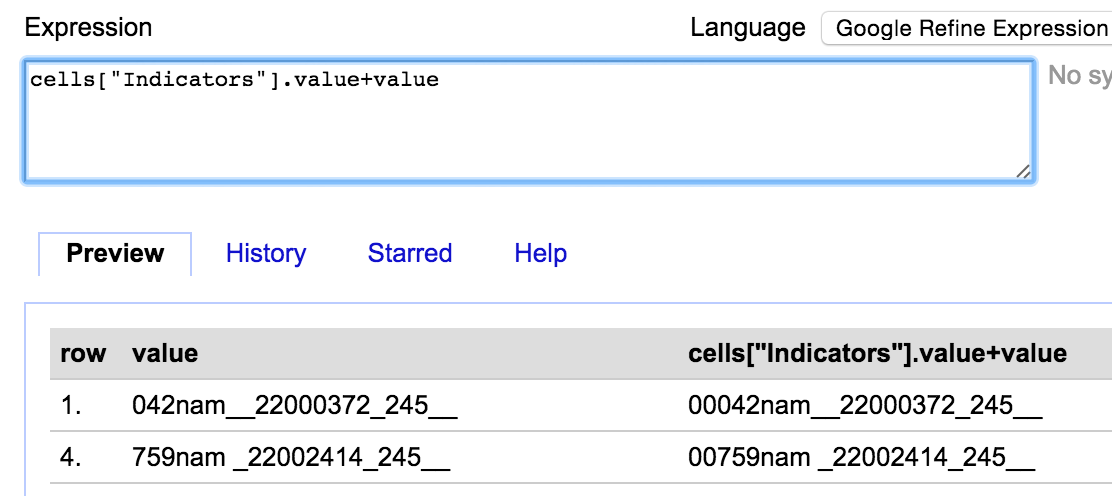
The ‘Row Template’ is the key part of the template – this defines how each row in the OpenRefine project is processed and output for the export. Inside the Row Template the text inside double curly brackets {{ }} is processed as a GREL expression – so you can manipulate the data as you output it if you need to – this makes the template extremely flexible. Because the export doesn’t relate to any single column you have to use the ‘cells[“Column name”].value’ syntax to bring in the values from the cells.
The default is to use a ‘jsonize’ function – which essentially makes sure that the data from a cell is valid for a JSON output file. However, in this case we don’t want to mess with the data on output – we just want the values, with the additional text required for the mnemonic MARC format.
So the row template I need to use is:
={{cells["Tag"].value}} {{cells["Indicators"].value}}{{cells["Content"].value}}
Because some lines will have values in the Indicators column and some won’t (the fixed fields), we have to sure that the indicators are populated (even if uncoded) for all non-fixed fields, and contain an empty string for fixed fields. As long as this is the case, the output will be formatted correctly for both types of field.
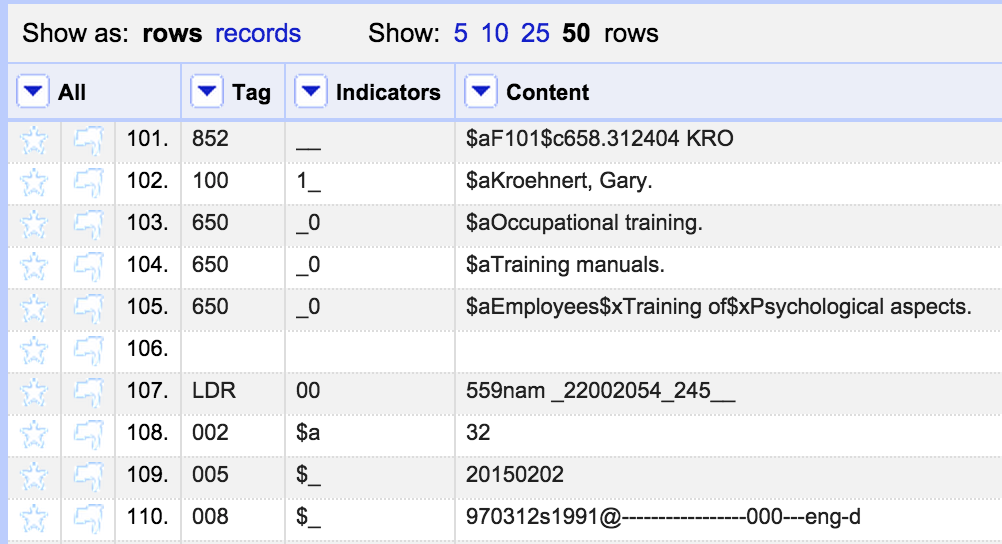
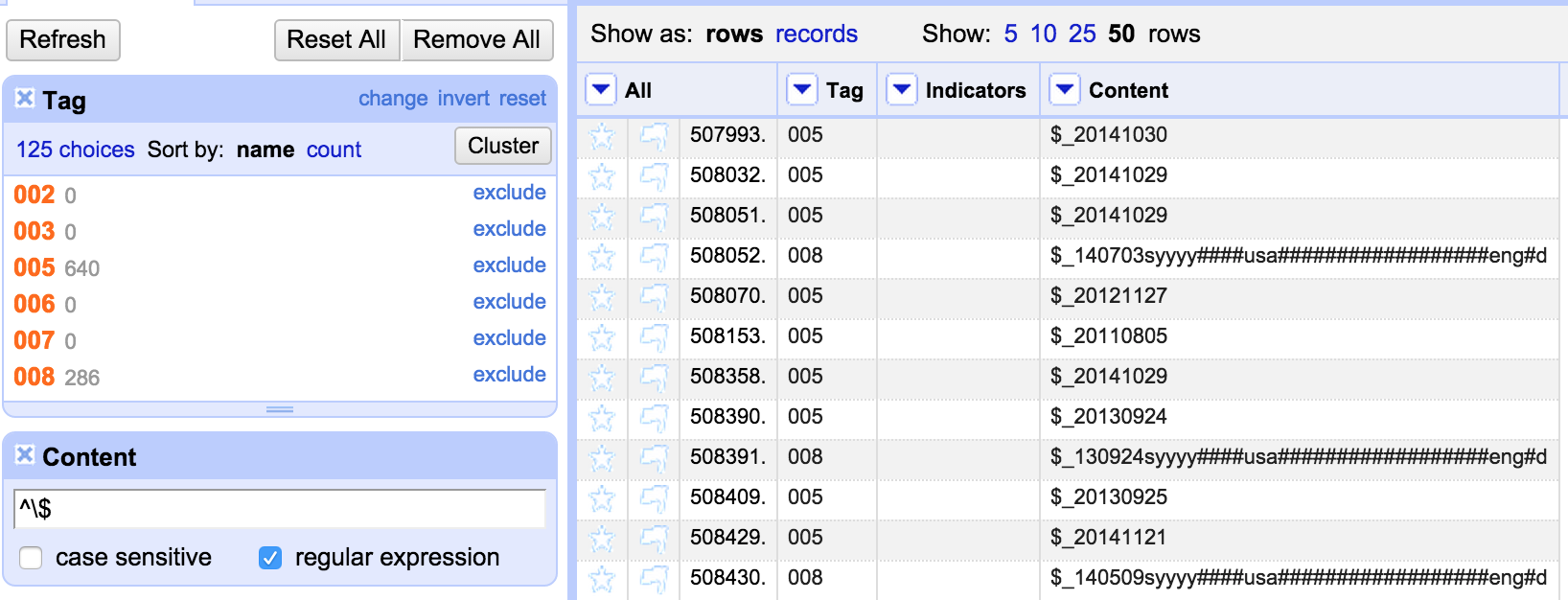
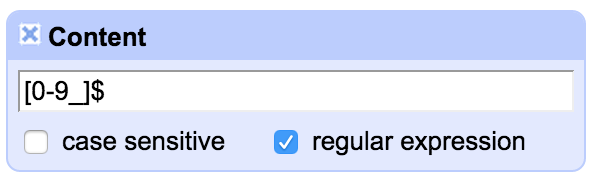
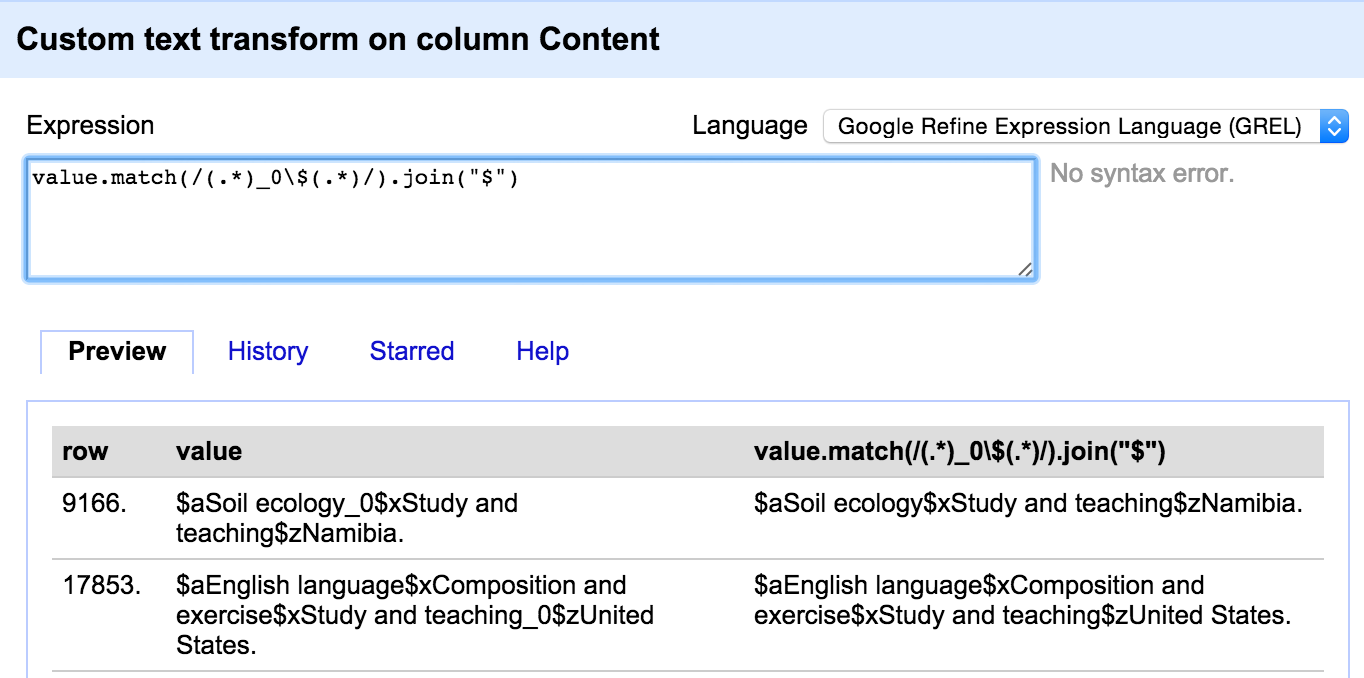
One thing to look out for is that there are a few different ways in which a field can appear ‘blank’ – it can be an empty string (“”) or ‘null’ or an error. In the export template any cells containing a ‘null’ rather than an empty string will appear as ‘null’ – as can be seen in the last row in this screenshot:
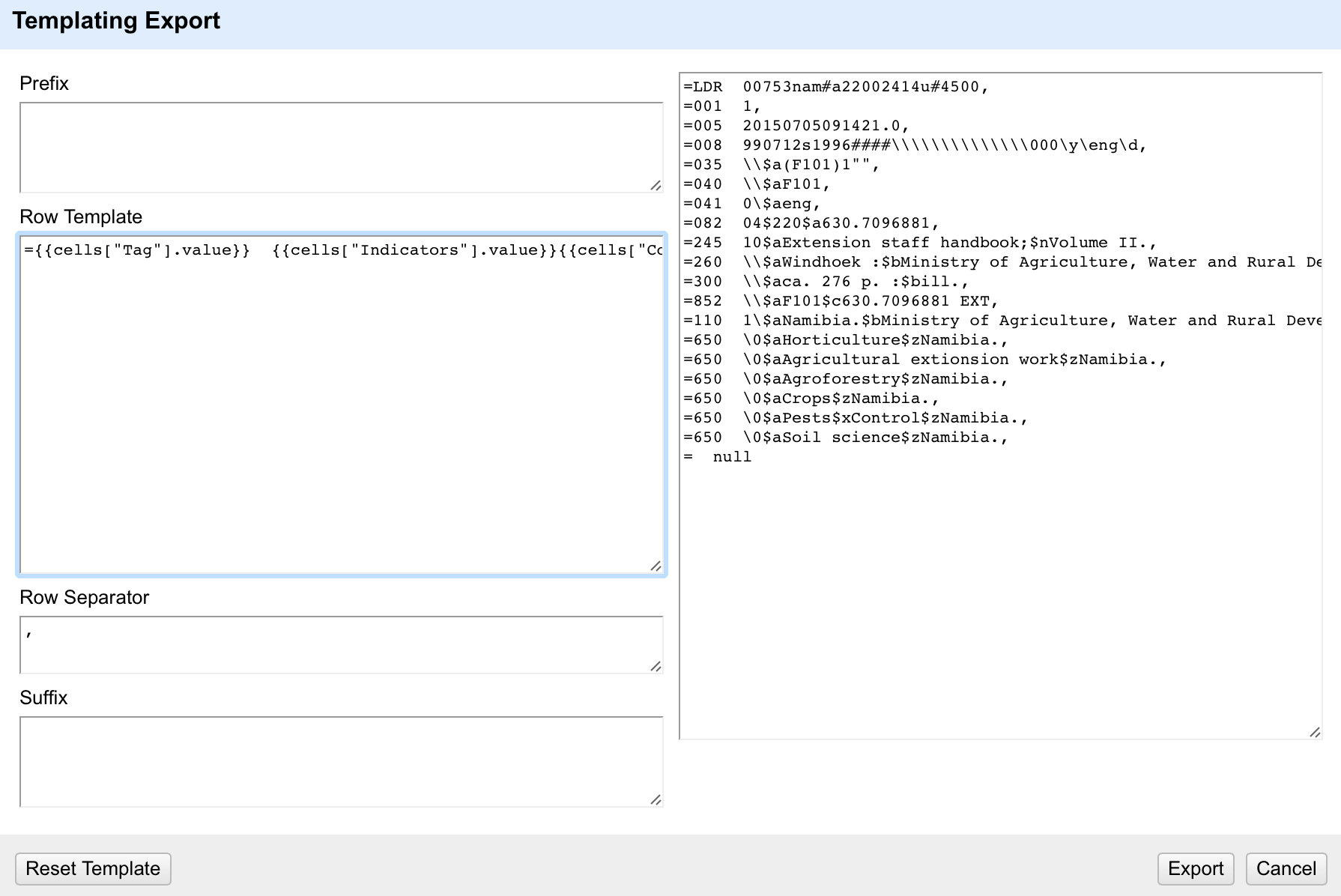
To avoid these ‘null’ values appearing you can either do a cell transformation on the appropriate columns to replace ‘null’ with “”, or you can write tests for ‘null’ values and replace them with blanks within the template using GREL expressions.
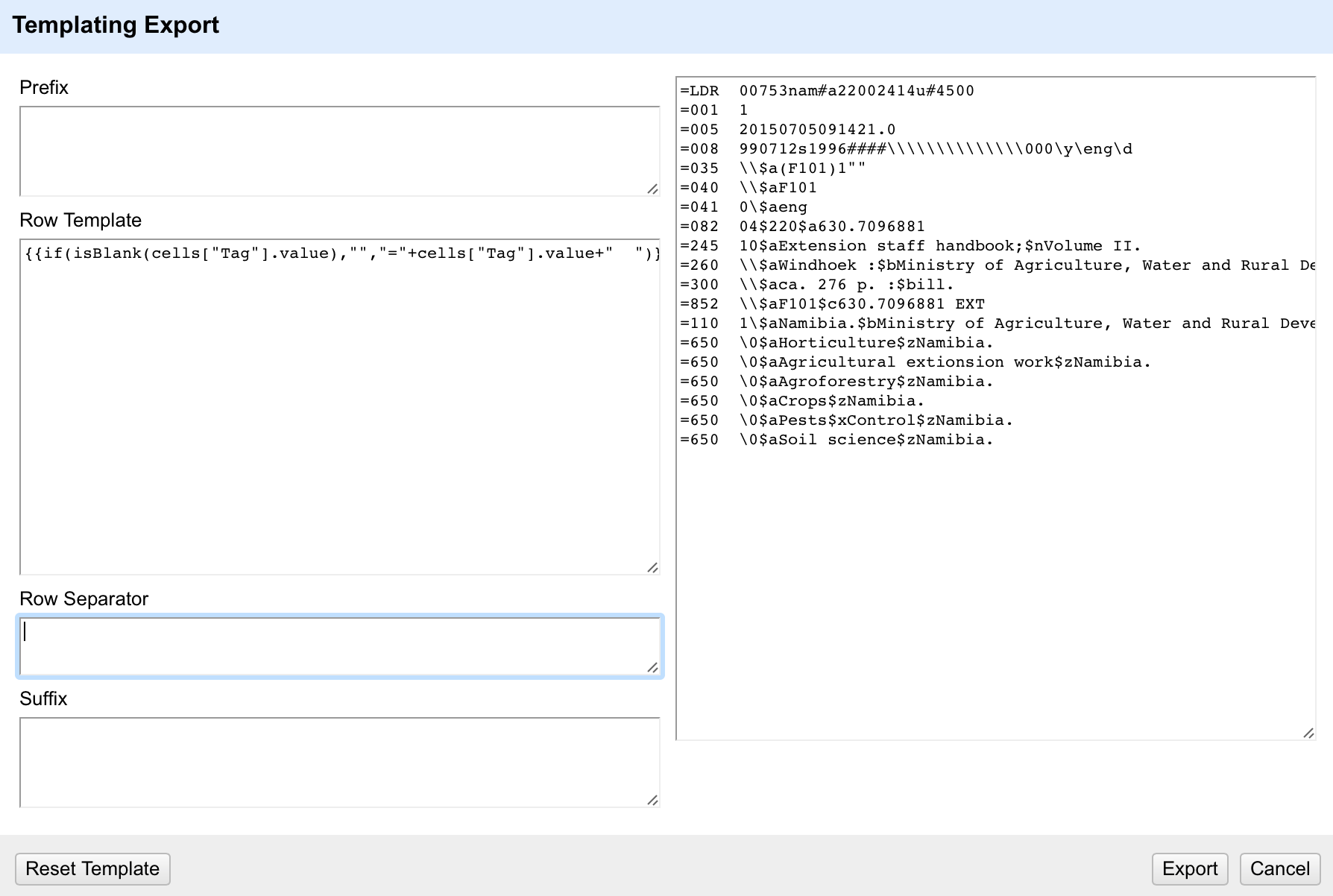
The other issue I’ve got here is that the ’empty’ line at the end of the record still starts with an ‘=’ sign – because I’ve set this to output on every row – and it doesn’t care that the row is blank. I could decide to not worry about this and edit out these lines after the export (e.g. in a text editor using find/replace on lines only consisting of an equals sign and two spaces). Alternatively I can write GREL in my template that checks to see if there is a value in the Tag column before outputting the equals sign and spaces. If I put this together with a check for ‘null’ values I get a more complex expression:
{{if(isBlank(cells["Tag"].value),"","="+cells["Tag"].value+" ")}}{{if(isBlank(cells["Indicators"].value),"",cells["Indicators"].value)}}{{if(isBlank(cells["Content"].value),"",cells["Content"].value)}}
This tests if the Tag cell in the row is blank and only outputs the ‘=’ at the start of the row and the two spaces following the tag if it finds a tag to use.
The final option on this screen is the ‘Row Separator’. In the default this is a comma followed by a newline/enter (which is of course difficult to see in the editor). I don’t need the comma at the end of each line but I do need a newline (otherwise all the rows would merge together). So I end up with:
Unfortunately there is no way of saving the Template within OpenRefine (although it will persist between sessions, but if you are using different templates at different times, this won’t help). If I’ve got a complex export I usually create a text file with each part of the export template (prefix, suffix, row template, row separator) documented. This would be important if you were doing a complex export like this OpenRefine MODS export template.
I can now export the the file in mnemonic MARC format by clicking Export. It will download as a text file with a ‘txt’ extension. I will want to rename the file with an ‘mrk’ extension so that MarcEdit recognises it as a mnemonic MARC file.
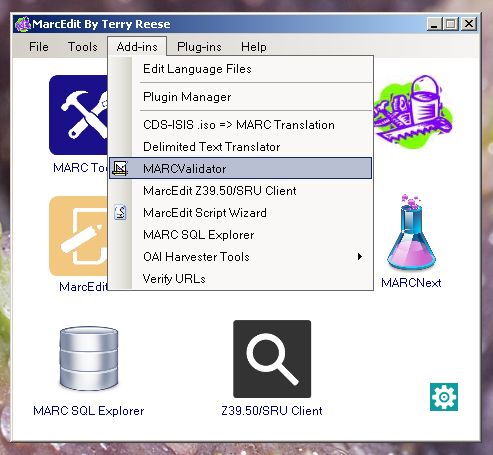
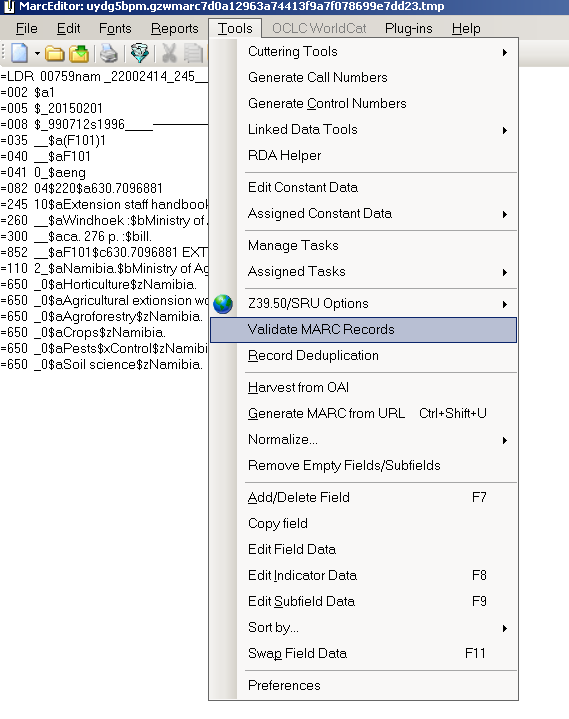
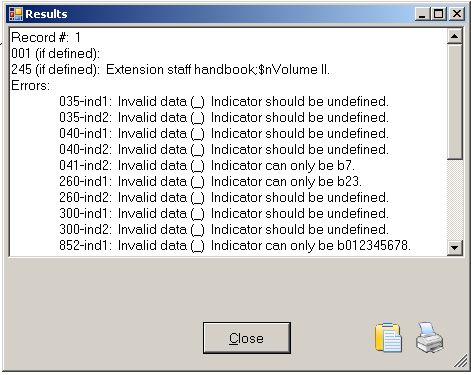
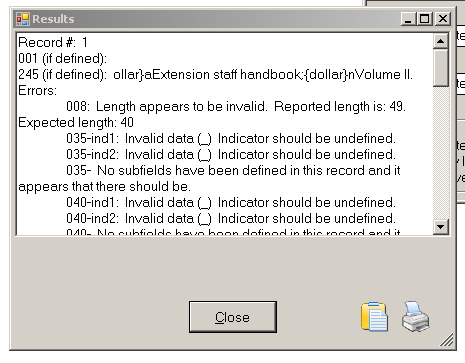
My final step is to use MarcEdit to do a final validation of this file (happily this found only one outstanding error which I was able to correct directly in the MarcEdit Editor), and finally I can use one of several routes in MarcEdit to covert the mnemonic MARC file to a proper MARC file (you can do this using the ‘MARC Maker’ function, using ‘Save as’ or ‘Compile File to MARC’ options in the Marc Editor).
And that’s it – a worked example of fixing MARC records using a combination of three tools – the Notepad++ text editor, MarcEdit and OpenRefine. I’d like to re-iterate my thanks to the Polytechnic of Namibia Library for giving me permission to share this example.
Finally – if there are things that I’m missing here, steps that could be improved/more efficient, questions to ask or clarifications to make please leave comments here or contact me on Twitter – I’m @ostephens.

{kind=link}